K3S
Author: Amr Ragab
INTRODUCTION
At Crusoe Cloud, our customers are building and operating orchestrated compute clusters for ML training, inference, and high-performance computing (HPC) at scale. To facilitate their journey, we're committed to delivering solutions that simplify cluster setup and configuration. In our last blog post, we covered deploying SLURM-orchestrated ML clusters using our Terraform provider. This installment details how to deploy a self-managed Kubernetes-based ML platform, leveraging Rancher K3S, Crusoe instances powered by NVIDIA H100 Tensor Core GPUs and NVIDIA Quantum-2 InfiniBand networking.
DEPLOYMENT
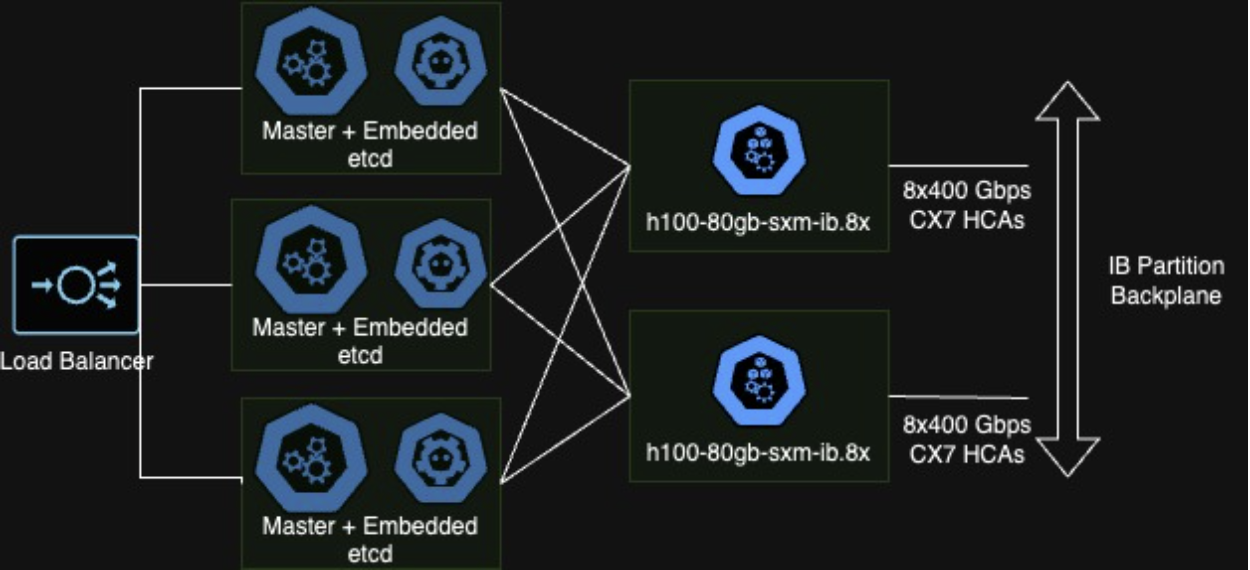
The architecture that will be deployed is summarized below. In brief, we will instantiate a 3 - node Rancher K3s control plane with an embedded API server, scheduler, and embedded etcd datastore on Crusoe's c1a instance family. Then the automated deployment will also launch an additional CPU instance to use as the HAProxy-based load balancer. Finally a variable number of workers will be deployed as a static cluster of Crusoe instances powered by NVIDIA H100 GPUs with InfiniBand.
The assets for the deployment are located here:
https://github.com/crusoecloud/crusoe-ml-k3s
Before beginning the deployment, install the Crusoe Cloud CLI and Terraform provider configured for API access into the account. Ensure the kubectl binary and Helm are installed and configured. In the locals section of the main.tf file, modify the variables listed below according to your environment - pay particular attention to the ssh values and ib_partition_id:
locals {
my_ssh_privkey_path="</path/to/priv.key>"
my_ssh_pubkey="<pub-key>"
worker_instance_type = "h100-80gb-sxm-ib.8x"
worker_image = "ubuntu22.04-nvidia-sxm-docker:latest"
ib_partition_id = "<ib_partition_id>"
count_workers = 2
headnode_instance_type="c1a.8x"
deploy_location = "us-east1-a"
...
} We recommend using Crusoe’s curated images as Crusoe keeps the NVIDIA driver and OFED drivers up to date for optimal performance. And downstream configuration is simpler for K3s.
Once the locals have been set execute the deployment by running:
terraform init
terraform plan
terraform apply
The deployment will take a few minutes to complete. Control plane nodes will likely be instantiated first, with GPU worker nodes taking up to 7 minutes to complete instance configuration. While worker nodes are being configured, you can retrieve the K3S client configuration file from the “crusoe-k3s-0” instance, which is the first control plane node created for the cluster. SSH into the instance and download the file, located at:
/etc/rancher/k3s/k3s.yaml
Replace the server address: in the YAML file with the Load Balancer public IP address which can be extracted from the output of the terraform deployment or the Crusoe Cloud Instance Console.
server: https://204.52.27.168:6443
With the control plane nodes and worker nodes configuration bootstrapped, the H100 instances run kubectl get nodes, expect the following output:
NAME STATUS ROLES AGE VERSION
crusoe-k3s-0 Ready control-plane,etcd,master 51m v1.28.4+k3s2
crusoe-k3s-1 Ready control-plane,etcd,master 51m v1.28.4+k3s2
crusoe-k3s-2 Ready control-plane,etcd,master 51m v1.28.4+k3s2
crusoe-k3s-worker-0 Ready <none> 46m v1.28.4+k3s2
crusoe-k3s-worker-1 Ready <none> 46m v1.28.4+k3s2
Now you can prepare the workers to run ML training jobs. To accomplish this, install the NVIDIA GPU Operator which will advertise H100 GPUs to the K3s API server for allocation. Additionally, install the NVIDIA IB SR-IOV Network Operator which will configure and advertise the IB HCAs to the control plane for allocation.
First, add the NVIDIA repo to Helm.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
Next, install the GPU operator, enabling `nvidia_peermem` kernel driver for GPUDirectRDMA over IB and utilizing the host MOFED drivers.
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator --set driver.rdma.enabled=true --set driver.rdma.useHostMofed=true
Finally, install the NVIDIA Network Operator. The configuration yaml is found in the Github repo cloned earlier.
helm install network-operator nvidia/network-operator -n nvidia-network-operator --create-namespace -f ./gpu-operator/values.yaml --wait
After a few moments, the GPU and Network Operator plugins will complete the configuration. Once the stack is ready the kubectl describe node crusoe-k3s-worker-0, the nvidia.com/gpu:8 and nvidia.com/hostdev:8 will be allocatable, indicating the GPUs and IB HCAs are being advertised respectively:
Allocatable:
cpu: 176
ephemeral-storage: 126353225220
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 990737488Ki
nvidia.com/gpu: 8
nvidia.com/hostdev: 8
pods: 110
VALIDATION
With the configuration complete, below are some quick validations to ensure that the stack is set up correctly for large scale ML training; checking the NCCL collective performance. Crusoe Cloud maintains curated Docker images at this Docker Hub repository:
https://hub.docker.com/u/crusoecloud
For multi-node tests install Kubeflow's MPI Operator:
kubectl apply -f https://raw.githubusercontent.com/kubeflow/mpi-operator/v0.4.0/deploy/v2beta1/mpi-operator.yaml
Next in the github cloned earlier in the `/examples` directory we have the NCCL tests yaml definition. This example will run the nccl-tests to confirm multi-node communication. It uses MPI for bootstrapping over the frontend networking, but will be using IB for the actual NCCL collective communication.
kubectl apply -f nccl-tests.yaml
In a few moments the pods will be in ContainerCreating and eventually Running on each of the workers. It may take some time for the launcher pod to get into Running state - but once there, get the logs for the NCCL tests.
kubectl logs -l training.kubeflow.org/job-role=launcher
A few notable lines in the log will confirm that multi-node training is set up correctly. To confirm that the image is correctly configured:
Ensure that NCCL 2.19 and above is being utilized for improved performance with NVIDIA H100 Tensor Core GPUs.
[1,0]<stdout>:NCCL version 2.19.3+cuda12.2
NVIDIA SHARP plugins from HPCX is loaded and that the IBext plugin is being utilized.
[1,0]<stdout>:nccl-tests-gdr-16-worker-0:42:100 [0] NCCL INFO Using network IBext
[1,17]<stdout>:nccl-tests-gdr-16-worker-2:43:101 [1] NCCL INFO Plugin Path : /opt/hpcx/nccl_rdma_sharp_plugin/lib/libnccl-net.so
[1,17]<stdout>:nccl-tests-gdr-16-worker-2:43:101 [1] NCCL INFO P2P plugin IBextThe NCCL_TOPO_FILE is set and being used with the Crusoe H100-based instances.
NCCL INFO NCCL_TOPO_FILE set by environment to /opt/h100-80gb-sxm-ib.xml
Correct IB HCAs are being utilized.
[1,28]<stdout>:nccl-tests-gdr-16-worker-3:46:102 [4] NCCL INFO NET/IB : Using [0]mlx5_0:1/IB/SHARP [1]mlx5_1:1/IB/SHARP [2]mlx5_2:1/IB/SHARP [3]mlx5_3:1/IB/SHARP [4]mlx5_5:1/IB/SHARP [5]mlx5_6:1/IB/SHARP [6]mlx5_7:1/IB/SHARP [7]mlx5_8:1/IB/SHARP [RO]; OOB eth0:10.42.5.16<0>
Send/Receive channels over GPUs on different instances are utilizing GPUDirect RDMA (GDRDMA).
[1,15]<stdout>:nccl-tests-gdr-16-worker-1:51:101 [7] NCCL INFO Channel 07/0 : 6[6] -> 15[7] [receive] via NET/IBext/3/GDRDMA
[1,15]<stdout>:nccl-tests-gdr-16-worker-1:51:101 [7] NCCL INFO Channel 15/0 : 6[6] -> 15[7] [receive] via NET/IBext/3/GDRDMA
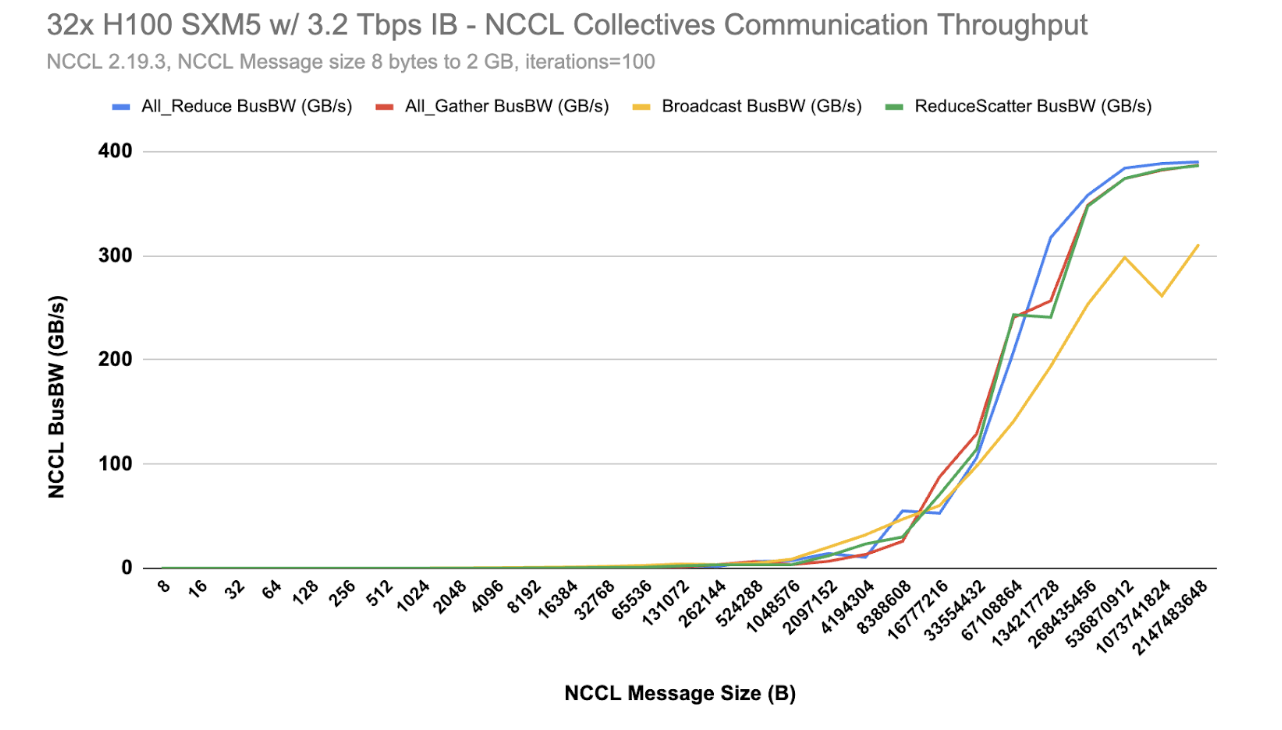
[1,1]<stdout>:nccl-tests-gdr-16-worker-0:43:101 [1] NCCL INFO Channel 01/0 : 24[0] -> 1[1] [receive] via NET/IBext/5/GDRDMA.Finally, for the NCCL message sizes above 1GB you should get BusBW around 390 GB/s (3120 Gbps).
[1,0]<stdout>:# out-of-place in-place
[1,0]<stdout>:# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
[1,0]<stdout>:# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
[1,0]<stdout>: 1073741824 268435456 float sum -1 5380.5 199.56 386.65 0 5353.5 200.57 388.60 0
[1,0]<stdout>: 2147483648 536870912 float sum -1 10716 200.39 388.26 0 10659 201.47 390.34 0
Included below is a graph demonstrating results when executing these NCCL tests across 32x H100 GPUs utilizing our K3s Rancher deployment. A few collectives used across common ML algorithms have been chosen.
CONCLUSION
Kubernetes is a great open platform for training and deployment of ML models at scale, as it’s an open standard across cloud providers and on-premise infrastructure. With support for Kubernetes on Crusoe Cloud, it is easy to get started with our accelerated computing instances. Although we described a self-managed approach using Rancher K3s here, Crusoe’s roadmap includes a managed Kubernetes platform to eliminate some of the undifferentiated lifting described above, like the control plane deployment. Now go power up your ML training or inference workloads with Rancher K3s on Crusoe Cloud. And if you have any questions about this or anything else on Crusoe Cloud please contact [email protected].