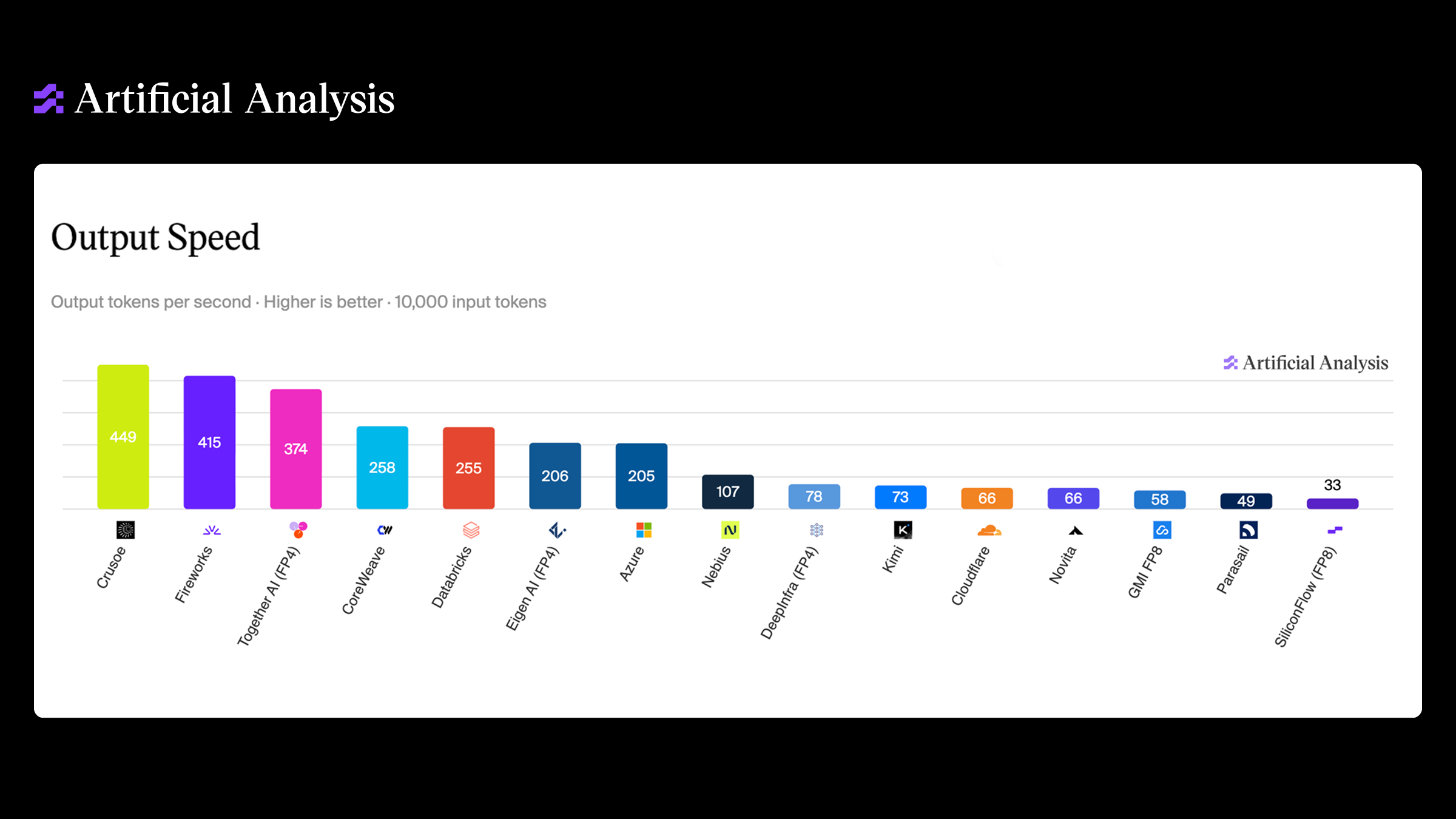
Scaling deep learning workloads with SLURM and NVIDIA Enroot, Pyxis on Crusoe Cloud
Large-scale distributed training requires the computational power of machine learning (ML) and high-performance computing (HPC) clusters, which serve as the backbone of cutting-edge artificial intelligence research and applications. These clusters are intricate infrastructures, often comprising thousands of interconnected CPUs and NVIDIA GPUs, optimized for deep learning workloads. They facilitate parallel processing and the handling of massive data throughput, essential for training complex neural networks and conducting sophisticated simulations. This, in turn, drives advancements in fields such as natural language processing, computer vision, and scientific research.
In this blog, we will introduce how to quickly get started with deploying ML clusters at scale using SLURM and the NVIDIA Enroot tool and Pyxis plugin.
Monitoring/Observability
The deployment will include a TPG (Telegraf-Prometheus-Grafana) stack with the Grafana UI hosted on the headnode of the cluster. This will allow you to monitor clusterwide resource utilization and drill down to individual instance resource consumption with near real-time observability (5sec).
Deployment
The resources needed to deploy the cluster on Crusoe are available here:https://github.com/crusoecloud/crusoe-hpc-slurm
In the github project, the main.tf contains the main terraform directives for provisioning the headnode. Create a variables.tf file that contains your API keys.
variable "access_key" {
description = "Crusoe API Access Key"
type = string
default = "<API KEY>"
}
variable "secret_key" {
description = "Crusoe API Secret Key"
type = string
default = "<SECRET KEY>"
}Next, in the main.tf file, locate the locals section and adapt it for your environment, replacing the ssh keys and instance type.
locals {
my_ssh_privkey_path="<path/to/private/key"
my_ssh_pubkey="ssh-ed25519 …<public key contents>"
headnode_instance_type="c1a.16x"
deploy_location = "us-east1-a"
}Execute the deployment by running it.
terraform init
terraform plan
terraform applyOnce terraform completes the deployement, connect (via http) to the <public-ip:3000> for access to the Grafana portal. In the Grafana dashboard, you can import any number of premade dashboards or create your own. I would recommend the System Metrics - Single Dashboard.
Connect (via ssh) the headnode to the public IP, and if the lifecycle script has completed, you can connect to the Slurm controller via the common Slurm commands.
ubuntu@crusoe-headnode-1:~$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
all* up infinite 1 idle crusoe-headnode-1
gpu up infinite 21 idle~ aragab-compute-[0-20]You will see that the status of the compute nodes are in idle~, which means that these are ephemeral nodes in the shutdown state. Once a job requesting resources is submitted, the startup command will launch the number of nodes needed to fulfill the job requirements. Once a job completes, after a time period, those instances will shut down automatically. The elapsed time of the shutdown is configurable in the slurm.conf file. And you can confirm that Enroot/Pyxis is set up by executing sbatch –help and checking that the pyxis third-party plugin is loaded like below:
Options provided by plugins:
--container-image=[USER@][REGISTRY#]IMAGE[:TAG]|PATH
[pyxis] the image to use for the container
filesystem. Can be either a docker image given as an enroot URI, or a path to a squashfs file onthe
remote host filesystem.
--container-mounts=SRC:DST[:FLAGS][,SRC:DST...]
[pyxis] bind mount[s] inside the container. Mount flags are separated with "+", e.g. "ro+rprivate"The main configuration file is located at /nfs/slurm/bin/slurm-crusoe-startup.sh, which sets up the ephemeral compute nodes. The main function calls the crusoe command line interface in that stanza. You can replace the instance type and modify other parameters, such as adding the IB partition ID.
crusoe compute vms create --name $1 \
--type h100-80gb-sxm-ib.8x --location us-east1-a \
--image ubuntu20.04-nvidia-sxm-docker:2023-10-24 \
--startup-script $TMPFILE --keyfile $CRUSOE_SSH_PUBLIC_KEY_FILE \
--ib-partition-id 6dcef748-dc30-49d8-9a0b-6ac87a27b4f8 >> $SLURM_POWER_LOG 2>&1The integration of Slurm’s power management module and the custom script instantiates resources. This mechanism creates an autoscaling environment with regard to the SLURM cluster. This can be a viable replacement until autoscaling is formally supported within Crusoe’s APIs.
If we submit an example job below:
#!/bin/bash
#SBATCH --job-name="test-nccl"
#SBATCH --nodes=1
#SBATCH --cpus-per-task=22
#SBATCH --exclusive
#SBATCH --ntasks-per-node=8
#SBATCH --partition=gpu
#SBATCH --gres=gpu:8
#SBATCH --container-image="nvcr.io#nvidia/pytorch:23.09-py3"
#SBATCH --output="pytorch-%j.out"
ulimit -l unlimited
export NCCL_DEBUG=INFO
python3 -c "import torch; print(torch.__version__)"
ls -l /dev/infiniband
nvidia-smiWe can import any public image or configure $ENROOT_CONFIG_PATH/.credentials to authenticate against a private registry and pass the --container-image directive to srun or sbatch. With this the image will be downloaded and enroot's hooks will run to pass through the GPU devices, infiniband interfaces and relevant paths to ensure ease of use when scaling containers across the cluster.
pyxis: imported docker image: nvcr.io#nvidia/pytorch:23.09-py3
2.1.0a0+32f93b1
total 0
crw------- 1 nobody nogroup 231, 64 Nov 13 18:34 issm0
crw------- 1 nobody nogroup 231, 65 Nov 13 18:34 issm1
crw------- 1 nobody nogroup 231, 66 Nov 13 18:34 issm2
crw------- 1 nobody nogroup 231, 67 Nov 13 18:34 issm3
crw------- 1 nobody nogroup 231, 68 Nov 13 18:34 issm4
crw------- 1 nobody nogroup 231, 69 Nov 13 18:34 issm5
crw------- 1 nobody nogroup 231, 70 Nov 13 18:34 issm6
crw------- 1 nobody nogroup 231, 71 Nov 13 18:34 issm7
crw------- 1 nobody nogroup 231, 72 Nov 13 18:34 issm8
crw-rw-rw- 1 nobody nogroup 10, 58 Nov 13 18:34 rdma_cm
crw------- 1 nobody nogroup 231, 0 Nov 13 18:34 umad0
crw------- 1 nobody nogroup 231, 1 Nov 13 18:34 umad1
crw------- 1 nobody nogroup 231, 2 Nov 13 18:34 umad2
crw------- 1 nobody nogroup 231, 3 Nov 13 18:34 umad3
crw------- 1 nobody nogroup 231, 4 Nov 13 18:34 umad4
crw------- 1 nobody nogroup 231, 5 Nov 13 18:34 umad5
crw------- 1 nobody nogroup 231, 6 Nov 13 18:34 umad6
crw------- 1 nobody nogroup 231, 7 Nov 13 18:34 umad7
crw------- 1 nobody nogroup 231, 8 Nov 13 18:34 umad8
crw-rw-rw- 1 nobody nogroup 231, 192 Nov 13 18:34 uverbs0
crw-rw-rw- 1 nobody nogroup 231, 193 Nov 13 18:34 uverbs1
crw-rw-rw- 1 nobody nogroup 231, 194 Nov 13 18:34 uverbs2
crw-rw-rw- 1 nobody nogroup 231, 195 Nov 13 18:34 uverbs3
crw-rw-rw- 1 nobody nogroup 231, 196 Nov 13 18:34 uverbs4
crw-rw-rw- 1 nobody nogroup 231, 197 Nov 13 18:34 uverbs5
crw-rw-rw- 1 nobody nogroup 231, 198 Nov 13 18:34 uverbs6
crw-rw-rw- 1 nobody nogroup 231, 199 Nov 13 18:34 uverbs7
crw-rw-rw- 1 nobody nogroup 231, 200 Nov 13 18:34 uverbs8
Mon Nov 20 17:06:57 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.12 Driver Version: 535.104.12 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H100 80GB HBM3 On | 00000000:11:00.0 Off | 0 |
| N/A 31C P0 71W / 700W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA H100 80GB HBM3 On | 00000000:12:00.0 Off | 0 |
| N/A 31C P0 72W / 700W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 2 NVIDIA H100 80GB HBM3 On | 00000000:13:00.0 Off | 0 |
| N/A 27C P0 72W / 700W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 3 NVIDIA H100 80GB HBM3 On | 00000000:14:00.0 Off | 0 |
| N/A 32C P0 71W / 700W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 4 NVIDIA H100 80GB HBM3 On | 00000000:21:00.0 Off | 0 |
| N/A 31C P0 71W / 700W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 5 NVIDIA H100 80GB HBM3 On | 00000000:22:00.0 Off | 0 |
| N/A 27C P0 71W / 700W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 6 NVIDIA H100 80GB HBM3 On | 00000000:23:00.0 Off | 0 |
| N/A 27C P0 75W / 700W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 7 NVIDIA H100 80GB HBM3 On | 00000000:24:00.0 Off | 0 |
| N/A 31C P0 74W / 700W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
Conclusion
Currently, the deployment only supports a homogeneous cluster, assuming that all compute nodes will be of the same instance type. Future work will continue to parameterize the deployment, exposing more options for configuration. Please watch our GitHub for updates and contact support if you have any questions. Now, go ahead and power up your compute cluster infrastructure on Crusoe Cloud. We would be excited to hear about the workloads you run on your ML/HPC cluster on Crusoe.