The Crusoe Cloud journey: Engineering the AI-first backbone


In Part I of our Crusoe Cloud journey, we discussed how the unprecedented demands of AI are creating a new dilemma for computing: balancing technological progress with climate impact. We shared our foundational architectural principle of building a neocloud from the ground up, designed to overcome the limitations of traditional networks for AI workloads.
Today, we're diving deeper into the technical heart of Crusoe Cloud: the evolution of our backbone network. Building an AI-first cloud means designing every layer with the unique demands of large-scale AI training and inference in mind. It's about engineering a network that's not just big, but smart, resilient, and purpose-built for the future of intelligence.
Building for Scale: Our Network Expansion Initiative
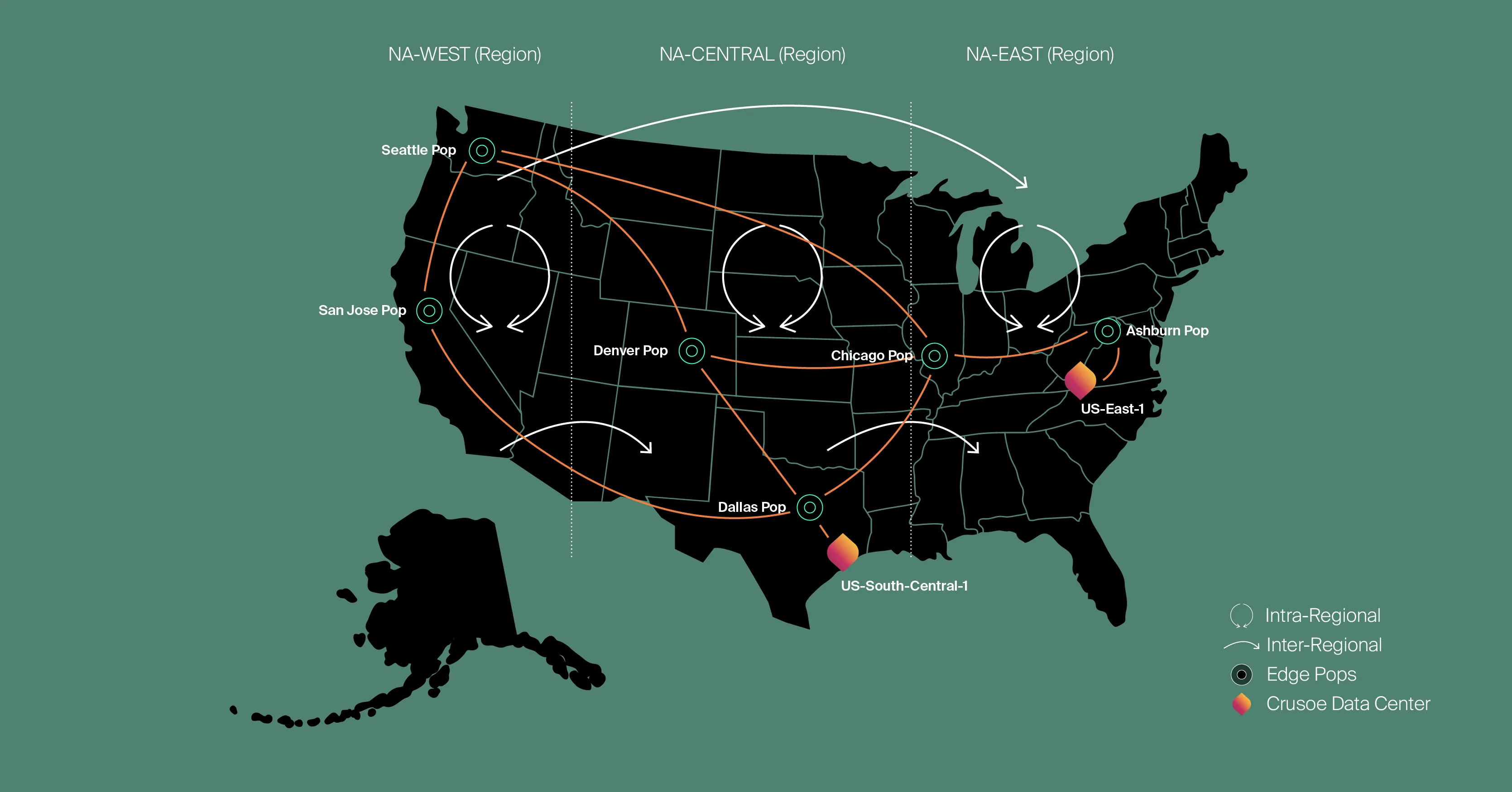
In early 2024, facing rapidly escalating demand from both internal and external customers, we launched a significant network expansion initiative. Our goal was ambitious: achieve a 10X scale increase, deliver ultra-high reliability (99.999% uptime), and significantly enhance user performance. Meeting these diverse needs required robust interconnectivity between Crusoe’s data centers and the strategic establishment of an edge network.
As part of this scaling effort, we meticulously explored cutting-edge networking technologies. We delved into Quality of Service (QoS) for intelligent traffic prioritization, Multi-Protocol Label Switching (MPLS) for dynamic traffic engineering, and IPv6 for future address space expansion. Crucially, we also revamped our entire routing architecture to support the immense, unpredictable growth of AI workloads.
Crafting a Smarter Routing Architecture
At the heart of any robust network lies its routing architecture. We made deliberate choices to ensure our network was not only scalable but also incredibly flexible and efficient for AI's unique demands.
We selected IS-IS (Intermediate System to Intermediate System) as our Interior Gateway Protocol (IGP). Why IS-IS? It offers a highly protocol-agnostic architecture, operating efficiently at OSI Layer 2, with seamless native support for both IPv4 and IPv6. This gives us immense flexibility for current and future addressing needs. Furthermore, IS-IS leverages Type Length Value (TLV) encoding within its Link State Packets. This extensibility is a game-changer, allowing us to carry various types of information and easily accommodate emerging protocols as AI networking continues to evolve.
Our Innovative iBGP Design
When it came to our internal BGP (iBGP) design, we faced a common challenge. While the route-reflector (RR) model is widely used, it has inherent limitations, particularly concerning path diversity. A major drawback is that RRs typically advertise only a single best path to their peers after receiving routes from clients. This can lead to uneven traffic distribution, as all traffic for a given prefix might be funneled to a single next-hop, rather than being intelligently balanced across multiple equal-cost paths.
We considered the Add-Path feature as a potential solution, which allows for the announcement of multiple paths. However, due to the critical need for rapid deployment and thorough testing, we opted to design a new iBGP architecture that moves entirely away from traditional route reflectors.
Our design process involved evaluating two primary options:
- Full Mesh iBGP Across All Routers: In this model, every router forms a direct iBGP peer relationship with every other router. This inherently solves the path diversity problem, as all routers learn every possible route. While ideal for smaller, static networks, it quickly becomes unscalable. As our network grows, the number of peering relationships, routes, and the associated memory and CPU demands on each router would become overwhelming.
- Full Mesh iBGP within Regions, with Route Reflectors Between Regions: This approach divides the backbone into smaller, manageable regions, where routers maintain a full iBGP mesh. Route reflectors would then handle route advertisement between these regions. While this mitigates some scaling concerns, it reintroduces the very limitations of route reflectors at the inter-region level, which we sought to avoid for AI's demanding traffic patterns.
Ultimately, we converged on a hybrid design that truly gives us the best of both worlds. We implemented a full mesh iBGP across all routers, combined with a regional segmentation of the backbone network, each equipped with tailored routing policies. This means that transit-provider routes (the bulk of our external traffic) are intelligently confined to their originating region, optimizing their path.
Meanwhile, other peering routes and internal data center traffic are flexibly advertised across regions. This innovative design effectively eliminates the path diversity limitations of route reflectors while robustly addressing the scaling challenges inherent in a purely full-mesh iBGP model.
Dynamic Traffic Management with MPLS-TE
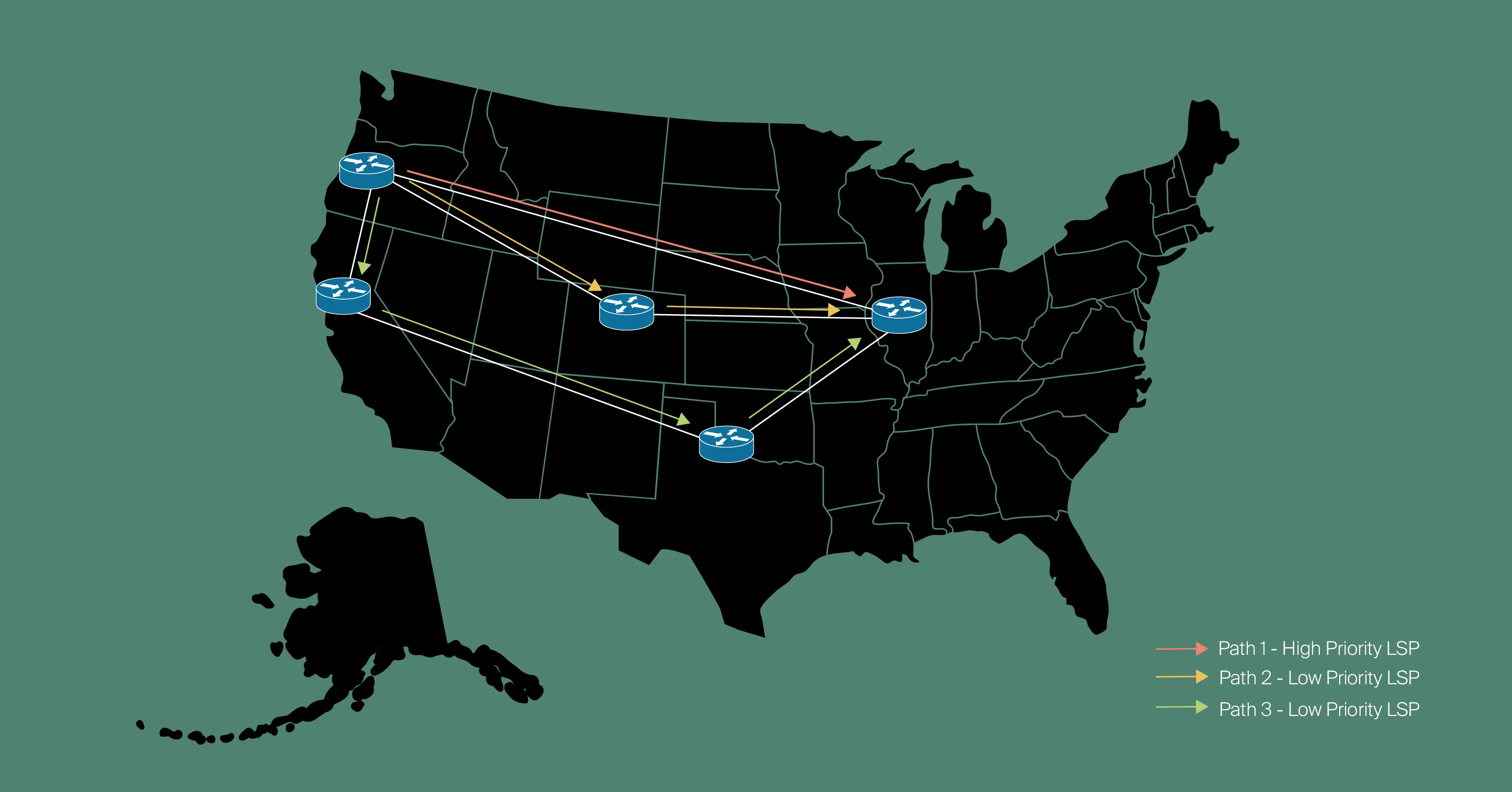
To meet current and anticipate future customer demands, especially for handling failures and sudden traffic spikes, we began deploying MPLS-TE (Multi-Protocol Label Switching - Traffic Engineering). This powerful technology enables our network to adapt dynamically to changes in bandwidth and demand, all without manual intervention.
We implemented MPLS with RSVP-TE (Resource Reservation Protocol - Traffic Engineering). This allows for automatic adjustment to traffic surges. When sufficient bandwidth is available, MPLS routes traffic along the shortest path by establishing a Label Switched Path (LSP) between source and destination. A key aspect of our design is the configuration of multiple LSPs with varying priorities: high-priority LSPs carry critical user traffic, while lower-priority LSPs handle less time-sensitive internal traffic.
As demand rises or network capacity decreases due to outages, RSVP-TE intelligently reroutes LSPs to alternate, higher-metric paths that have enough available bandwidth. Because our LSPs have different priorities, RSVP-TE always prioritizes preserving user traffic on the shortest, highest-priority paths, shifting less critical internal traffic to longer routes first. This proactive approach provides superior network redundancy, optimizes resource usage, and ensures consistent service quality without the need for costly over-provisioning.
Specialized Hardware for an AI-First Network
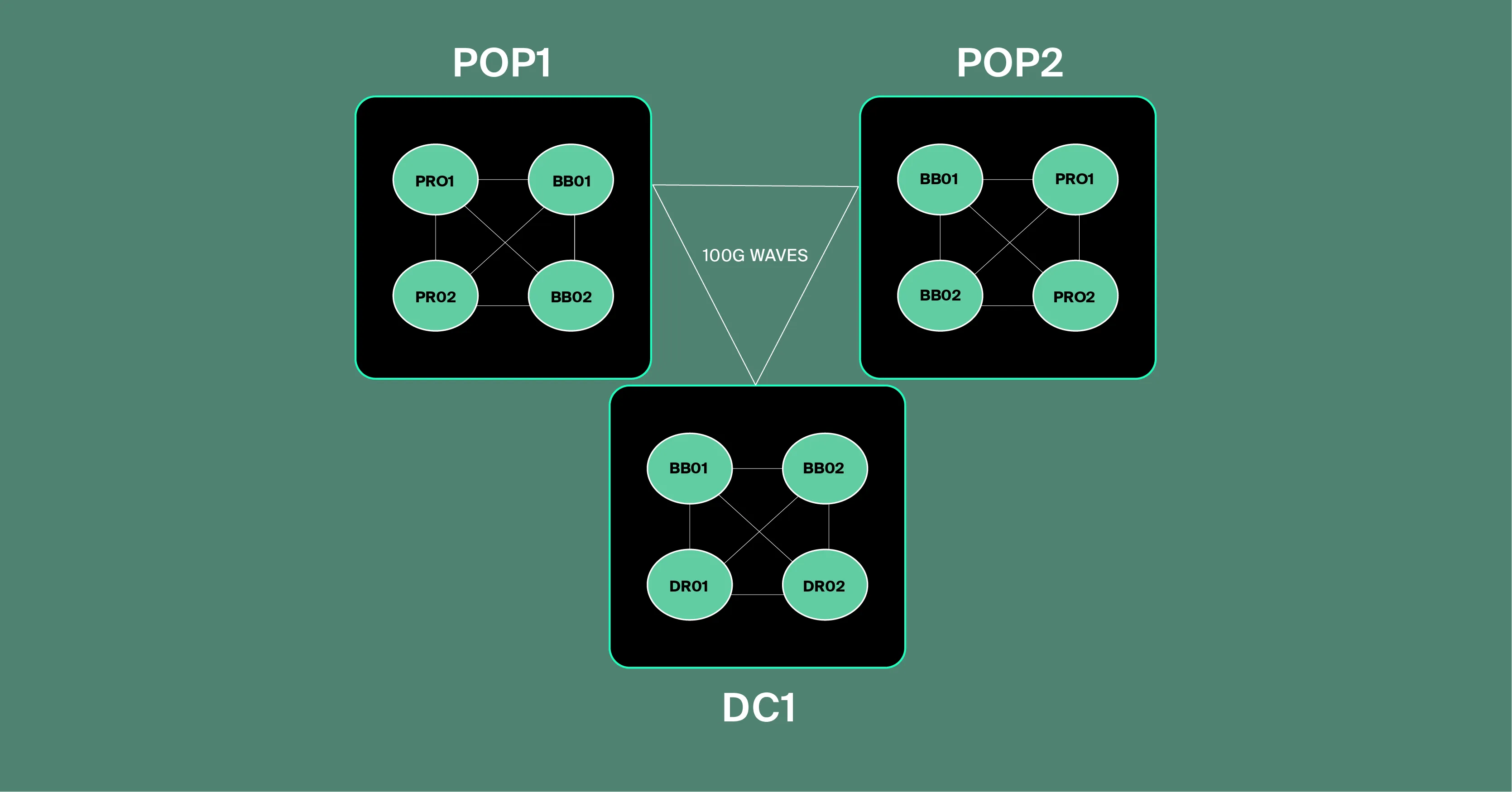
In this initial phase, Crusoe’s backbone network is composed of routers fulfilling three distinct and critical roles:
- Data Center Routers (DR): These are the entry and exit points, primarily responsible for linking our data centers directly to the robust backbone network.
- Backbone Routers (BB): These powerful routers serve as termination points for long-haul circuits and aggregate traffic from our data center routers within their respective regions. They form the core arteries of our network.
- Peering Routers (PR): These are our external gateways, primarily handling connections between Crusoe and external BGP peers to facilitate seamless Internet connectivity.
Our network is designed to carry various traffic types efficiently, from "customer traffic" flowing between Crusoe and the open Internet, to "data center traffic" exchanged among Crusoe’s own distributed facilities. Both traffic types traverse a single, unified network layer, sharing the same meticulously engineered architecture and devices. As traffic volumes continue to surge with the accelerating pace of AI, we continuously reassess and adjust our network design to meet these evolving demands, ensuring we're always ahead of the curve.
Building the Core for What's Next
Our journey to engineer the Crusoe Cloud backbone is a testament to our commitment to building an AI-first infrastructure that not only meets the demands of today but is also prepared for the innovations of tomorrow. We didn't just add more capacity; we designed a fundamentally smarter, more resilient, and highly specialized network.
Next Up: In Part 3 of this series, we'll shift our focus to the "Evolution of the Edge" — exploring how we're extending powerful AI compute capabilities closer to where data is generated and consumed, further optimizing performance and efficiency.
Ready to experience a cloud built for the future of AI? Explore Crusoe Cloud today.


